4 V’s of Big Data– Today finding important information is supercritical for each business. This type of information makes up large, complex disorganized, and organized data sets drawn out from appropriate resources and transmitted throughout shadow and on-premise limits.
This is known as “internet scraping for big data” where big data is a large quantity of both organized and disorganized content, and internet scraping is the activity of drawing out and transmitting this content from online resources.
The importance of big data is triggered by high-powered analytics prominent to wise business choices relates to cost and time optimizations, item development, marketing projects, issue discovery, and the generation of new business ideas. Let’s maintain reading to discover what big data is, in what measurements big data is broken, and how scraping for big data will help you get to your business objectives.
The Big Idea Behind Big Data
Big data is content that’s too large or too complex to handle by using standard processing techniques. But it becomes important, just if it’s protected, refined, comprehended, and used similarly.
The primary aim of big data removal is to obtain new knowledge and patterns that can be evaluated to earn better business choices and tactical moves. Besides, the analyses of data patterns will help you overcome expensive problems and anticipate client habits rather of thinking.
Another benefit is to outperform rivals. Current rivals as well as new gamers will use knowledge evaluation to contend, innovate and obtain income. And you need to maintain.
Big data enables to produce new development opportunities and most companies develop divisions to gather and analyze information about their services and products, customers and their choices, rivals, and industry trends. Each company attempts to use this content efficiently to find answers which will enable:
- Cost savings
- Time reductions
- Figure out the marketplace
- Control brand name reputation:
- Increase client retention
- Resolving advertising and marketing problems
- Product development
4 V’s of Big Data
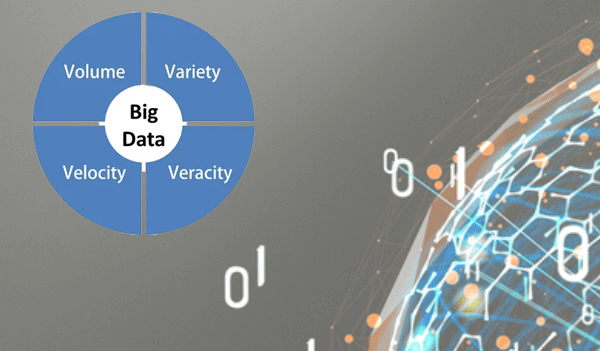
There are 4 v’s of big data on which big data is standing – quantity, variety, speed, and veracity. Let’s review every one in more information.
4 V’s of Big Data: Volume
volume is the significant characteristic while handling a load of information. While we measure routine information in megabytes, gigabytes, or terabytes, big data is measured in petabytes and zettabytes.
In the previous, content keeping was a problem. But today new technologies such as Hadoop or MongoDB make it occur. Without unique solutions for keeping and processing information, further mining would certainly not be feasible.
Companies gather huge information from various online resources, consisting of emails, social media, item reviews, and mobile applications. Inning accordance with experts, the dimension of big data will be increased every 2 years, and this definitely will require appropriate data management in the years to coming.
4 V’s of Big Data: Variety
The variety in huge content requires certain processing abilities and unique formulas, as it can be of various kinds and consists of both organized and disorganized content:
- Structured content consists of market numbers, stock understandings, monetary records, financial institution documents, item information, and so on This content is kept and evaluated with a help of traditional storage space and evaluation techniques.
- Unstructured content mainly reflects human ideas, sensations and feelings and is caught in video clip, sound, e-mails, messages, tweets, condition, pictures, pictures, blog sites, reviews, recordings, and so on. The collection of disorganized content is done by using appropriate technologies such as data scraping, which is used to browse webpages by getting to the maximum deepness to extract valuable information for further evaluation.
4 V’s of Big Data: Velocity
Today information is streaming at remarkable velocity, and companies must handle it in a prompt manner. To use the real potential of drawn out information, it should be produced and refined as fast as feasible. While some kinds of content can be still appropriate after some time, the huge part requires instant response such as messages on Twitter or Twitter and google messages.
4 V’s of Big Data: Veracity
Veracity has to do with the content quality that should be evaluated. When you deal with huge quantity, high speed, and such a large variety, for exposing truly significant numbers, you need to use advanced artificial intelligence devices. High-veracity data provide information that’s valuable to analyze, while low-veracity data includes a great deal of empty numbers commonly known as sound.
Scraping Big Data
For most entrepreneur to obtain a comprehensive quantity of information is a lengthy and instead humiliating job. But with a help of internet scraping, we can streamline this work. So let’s dig a bit deeper to understand how to obtain documents from internet resources by using data scraping.
Complex and large websites include a great deal of documents that’s important, but before use it, it’s necessary to copy to storage space and conserve in understandable style. And if we are discussing manual copy-paste, it’s virtually difficult to do it alone, especially if there mores than one website.
For circumstances, you might need to export a listing of items from Amazon.com and wait in Stand out. Through manual scraping you can’t accomplish the same efficiency as with a help of unique software devices. Besides, while scraping on your own, you’ll face up a great deal of challenges (lawful problems, anti-scraping methods, bot detections, IP obstructing, and so on) about which you do not also know.
Data scraping is based upon using unique scrapes to creep throughout specific websites and appearance for specific information. Consequently, we will have files and tables with organized content. When data awaits further evaluation, the following advanced analytics processes come right into play:
- Data mining, which displays data sets and searching patterns and relationships;
- Predictive analytics, that develops patterns to anticipate client habits or other approaching developments;
- Machine learning, which uses formulas to study quote data sets and deep learning, a advanced offset of artificial intelligence.
Using Big Data in Business
Big data has a considerable role on the planet of business and to understand its effect on business environment and produce a worth, it’s necessary to learn a little bit about data scientific research. Here are the best business methods where big data can be used:
- Risk Management – While companies are looking for a tactical approach to handle risk management, the use of big data can provide anticipating analytics for risk foresight.
- Understanding Customers – By using big data drawn out from social media communications, review websites and messages on Twitter, you’ll produce an appropriate customers account or determine your buyer personalities.
- Determine Rivals – Big data enables to know your rivals, what pricing models they have, or what their customers are feeling about them. Plus, you can learn how they are functioning on their client interactions.
- Stay Tuned with Trends – Big data will help to determine trends and take place with item development by evaluating how customers’ habits and buying patterns force on trends and how they’ll change in time.
- Marketing Strategy – By understanding your customers, you can develop effective projects to target a specific target market and obtain understandings to produce high-converting marketing products.
- Talent Purchase – Many thanks to big data, you can boost company’s human source management. You’ll have the complete information to hire the best individuals, arrange real trainings and boost staff satisfaction.
Big data option on the Microsoft SQL Server platform
Microsoft SQL Server 2019 Big Clusters is an add-on for the SQL Server Platform that lets you deploy scalable clusters of SQL Server, Spark, and HDFS containers running on Kubernetes.
These components work side-by-side to enable you to read, write, and process big data using the Transact-SQL or Spark libraries, enabling you to easily combine and analyze your high-value relational data with high-volume, non-relational big data.
Big data clusters also allow you to virtualize data with PolyBase, so you can query data from external SQL Server, Oracle, Teradata, MongoDB, and other data sources using external tables.
SQL Server 2019 Big Data Clusters add-on runs locally and in the cloud using the Kubernetes platform, for any standard Kubernetes deployment.
Additionally, the SQL Server 2019 Big Data Clusters add-on integrates with Active Directory and includes role-based access control to meet your company’s security and compliance needs.
SQL Server 2019 Big Data Clusters add-on deprecation
On February 28, 2025, we will be retiring SQL Server 2019 Big Data Clusters. All existing SQL Server 2019 users with Software Assurance will be fully supported on the platform and the software will continue to be maintained via SQL Server cumulative updates until then.
Changes to PolyBase support in SQL Server
Associated with the SQL Server 2019 Big Data Clusters deprecation are several features associated with scaling queries.
The PolyBase scaling group feature from Microsoft SQL Server has been deprecated. The scaling group functionality was removed from the product in SQL Server 2022 (16.x).
The in-market versions of SQL Server 2019, SQL Server 2017, and SQL Server 2016, continue to support functionality through the end of the product’s life. PolyBase data virtualization continues to be fully supported as a scaling feature in SQL Server.
Hadoop Cloudera (CDP) and Hortonworks (HDP) external data sources will also be retired for all in-market versions of SQL Server and are not included in SQL Server 2022.
Support for external data sources is limited to the product version in mainstream support by the respective vendors. It is recommended that you use the new object storage integration available in SQL Server 2022 (16.x).
In SQL Server 2022 (16.x) and later versions, users must configure their external data source to use the new connector when connecting to Azure Storage.
Understanding of Big Data Cluster architecture for replacement and migration options
To create replacement solutions for Big Data storage and processing systems, it’s important to understand what SQL Server 2019 Big Data Clusters provide, and their architecture can help inform your choices.
Functionality override options for Big Data and SQL Server
Operational data functions facilitated by SQL Server within Big Data Clusters can be replaced by on-premises SQL Server in a hybrid configuration or using the Microsoft Azure platform.
Microsoft Azure offers a choice of fully managed relational, NoSQL, and in-memory databases, spanning both proprietary and open source engines, to suit the needs of modern application developers.
Infrastructure management—including scalability, availability, and security—is automated, saving you time and money, and allowing you to focus on building applications while Azure managed databases make your work simpler by gaining performance insights through embedded intelligence, seamlessly scaling, and managing security threat
The next decision point is where to compute and store data for analytics. The two architectural choices are in-cloud and hybrid deployment. Most analytics workloads can be migrated to the Microsoft Azure platform.
Data “born in the cloud” (derived from Cloud-based applications) is a prime candidate for this technology, and data movement services can safely and quickly migrate large-scale local data.
Microsoft Azure has systems and certifications that enable secure processing of data and data across multiple tools.
In the In-cloud architecture option, all components reside in Microsoft Azure. Your responsibility lies with the data and code that you create for the storage and processing of your workloads. These options are discussed in more detail in this article.
- This option works best for multiple components for data storage and processing, and when you want to focus on data construction and processing rather than infrastructure.
In the hybrid architecture option, some components are maintained locally and other components are housed in the Cloud Provider. The connectivity between the two is designed for the best placement of redundant data processing.
- This option works best when you have sizable investments in on-premises technology and architecture, but you want to leverage Microsoft Azure’s offerings, or when you have processing and target applications that are on-premises or for a worldwide audience.
For more information about building scalable architectures, see Building scalable systems for massive data.
Read Also: